原文链接
Rendering Elimination: Early Discard of Redundant Tiles in the Graphics Pipeline
论文要解决的问题
由于帧与帧间的连续性,连续两帧的同一区域有可能相同,因此会产生大量的冗余计算,本文将尝试减少这种冗余计算,以提高TBR GPU的渲染效率。
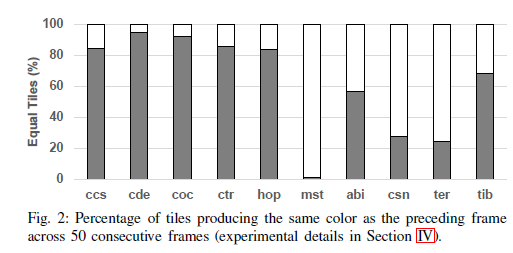
如下图是一组安卓游戏的两个连续帧之间平均相同的tile所占的百分比,以此可以看出,在传统的pipeline中连续帧之间存在大量的冗余计算。
传统Tile-Based架构
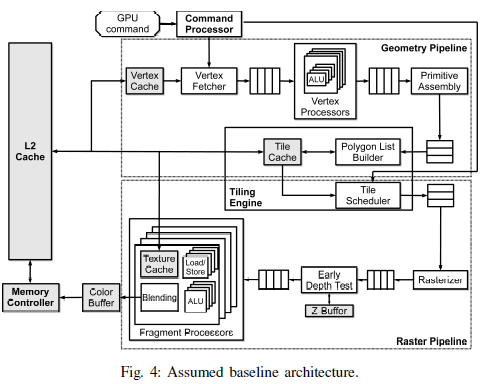
Command Processor:用于解析Drawcall和确定向pipeline提交的顶点数据的格式;
Vertex Fetcher:创建顶点的输入流(包括顶点的坐标和颜色等信息);
Vertex Processor:用于执行Vertex Shader;
Primitive Assembly:将顶点分组成三角形或其他原语,并执行裁剪(clipping)和剔除(culling)技术;
Polygon List Builder:将图元信息存储至Parameter Buffer中,这些信息以一种利用局部性并提高Raster性能的格式存储。该单元也决定每一个图元驻留在哪些tile中;
Tile Scheduler:负责获取给定tile的图元数据,并将其发送至Raster Pipeline;
Rasterizer:将三角形的顶点信息进行插值运算成片元(光栅化);
Early Depth Test:用于丢弃被先前片元遮挡的片元以使其不会被片元着色;
Fragment Processor:执行fragment shader;
Blending Unit:用于混合先前计算的颜色(用于半透明物体),并将最终结果放到Color Buffer中;
当一个tile的所有图元被计算完毕后,Color Buffer的数据将被刷到内存的Frame Buffer中,并执行下一个tile的Raster Pipeline;
本文所提的优化方式 Rendering Elimination
整体框架
首先可以确定的是,如果一个tile与上一帧的tile的输入包含相同的场景常量和所有覆盖该tile的图元的信息,则这一个tile的最终颜色将与上一个tile的最终颜色相同,因此可以绕过这个tile的整个Raster Pipeline。
但由于这一数据所占的空间很大,因此读取起来比较低效,因此通过对一个tile进行签名的方式进行对签名进行存储至Signature Buffer中。
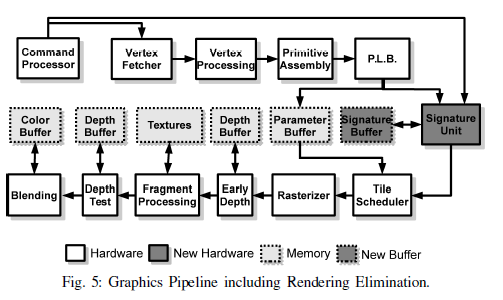
如上图,Signature Unit计算一个tile的签名,并将其存放在Signature Buffer中。与此同时,Polygon List Builder将图元数据存放在Parameter Buffer。当tile被调度到Raster Pipeline时,将检查该tile的签名是否与上一帧的签名进行对比,如果相同,则跳过Raster Pipeline,并不更新Frame Buffer。
实现需求
由于每一个图元都有可能覆盖任何一个tile。这导致只有所有几何数据都被处理完才能知道这个tile的完整输入,以计算签名。这需要在计算签名时重新将这个tile的数据从Parameter Buffer中读出并进行计算,这是十分低效的。因此,本文提出一种,增量的签名计算方式。无论图元以什么顺序,发送至Signature Unit,该单元将之前的签名与当前场景常量或原语的顶点数据通过如下算法进行计算,并将其重新写到Signature Buffer中。只要最终的tile相同,则该签名值便相同。由于签名的计算和Geometry Pipeline阶段相互重叠,因此可以节省大量的时间。

此外,本文做了大量实验,没有发现一例hashing冲突的结果。
Tabled-based CRC32 Computation
由于计算CRC32需要花费较长的时间,因此为加速这一过程,可以所有可能输入对应的预计算结果存入Look-up Table中,然而如果消息B的长度为n,则需要2n。因此将输入的消息B划分为B1…Bkk个一字节的块,每个块对应一个LUT,在减少存储的同时,提高了计算效率。
其中第一个块的LUT为B1后面跟k-1个字节的0的输入对应的CRC32,第二个块的LUT为B2后面跟k-2个字节的0的输入对应的CRC32,以此类推。消息B对应的CRC32为这几个LUT中的结果的异或。
Tile输入字节流的结构
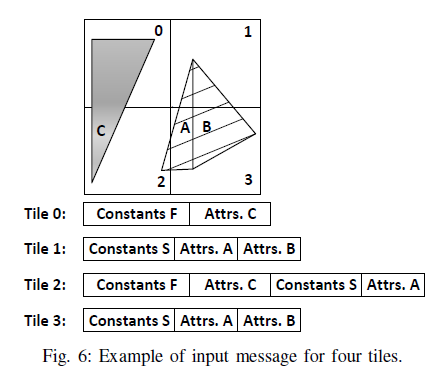
如上图所示,若需要两个Drawcalls:Drawcall F(fill,C)和Drawcall S(stripes,A,B)时,其结构如图下方tile的输入字节流结构。
Signature Unit(SU) Architecture
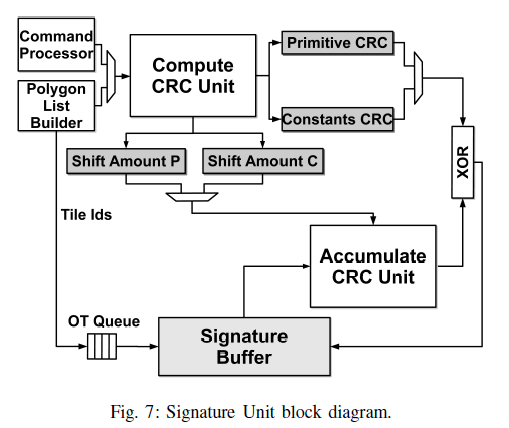
当SU接收到一个新的数据块时,需要计算它的CRC并通过增量的方式更新所有该数据块覆盖的tile的CRC。
对于顶点信息:
- SU使用Compute CRC Unit计算该图元所有的顶点信息的签名,结果被存在Primitive CRC Register中。
- 由于顶点信息的属性数量是可变的,以此将该数据块的长度存在Shift Amount P Register中。
- 利用Polygon List Builder将所有该图元覆盖的tile的id存在OT Queue中。
- 在计算完该图元的签名后,Signature Unit遍历所有OT Queue的Tile id,并从Signature Buffer中读取对应id的CRC签名,将其发送至Accumulate CRC unit中,此外图元消息的长度也被发往该单元,以此计算算法1中的CRCTemporary。
对于常量信息:
与顶点处理信息方式类似,但签名需存在Constant CRC Register中,长度需存在Shift Amount C Register中。
由于相同Drawcall的多个图元可能会覆盖相同的tile,但对应的场景常量每个tile中只能被考虑以此。
因此本文使用位图的方式以解决该问题。该位图的长度与tile的数量相等。当位图中的一个位置被设置,则说明对应tile的场景常量签名已经被计算过。当GPU处理下一个Drawcall时,位图需要被清空。
在遍历OT Queue时,首先检查该tile的对应位是否被设置,若被设置,只需要通过Primitive CRC进行更新CRC;否则,设置该位,并更新两次CRC,第一次利用Constanta CRC进行更新,第二次利用Primitive CRC进行更新。
Compute CRC 和 Accumulate CRC Unit的结构
Compute CRC Unit
用于实现算法1循环中的前两步。
由于每个数据块的长度不固定,因此将其拆分为64bit的固定长度,并利用算法2计算CRC。

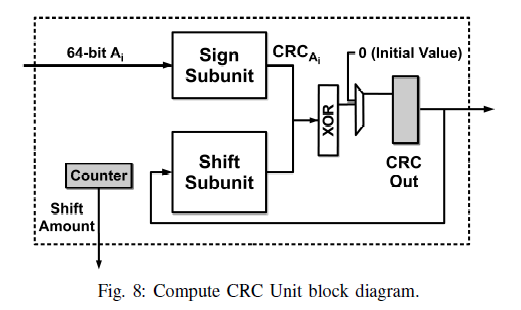
其中CRCout存入Primitive CRC或Constant CRC中,ShiftAmount存入Shift Amount P或Shift Amount C中。
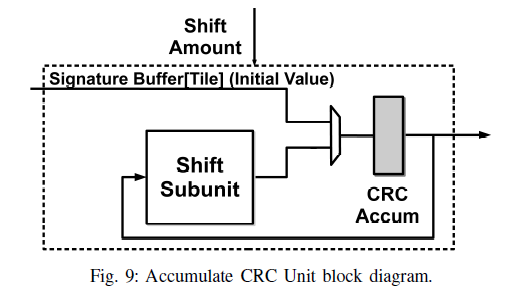
Accumulate CRC Unit
用于实现算法1循环中的第3步
由于数据块的长度不固定,左移的量也不固定,因此需要采用增量的方法计算CRC,如算法3所示。

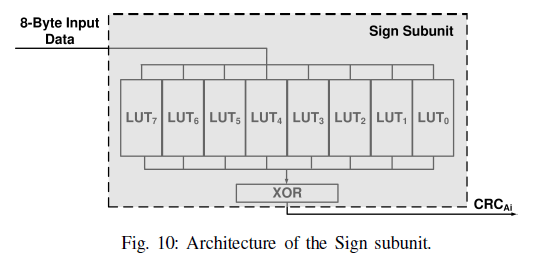
Sign subunit
Sign subunit对64bit的字块使用如Tabled-based CRC32 Computation小节所述的方法,每一个字节对应一个LUT,因此只需要8个LUT即可,其输出结果为8个LUT结果的异或。
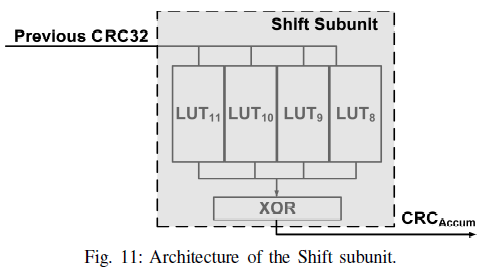
Shift subunit
与Sign Subunit结构类似,由于CRC32为32位,而且左移只需要在后面补0即可,因此实际计算的CRCAccum只与这32位有关。
评估方法
GPU模拟框架:Teapot
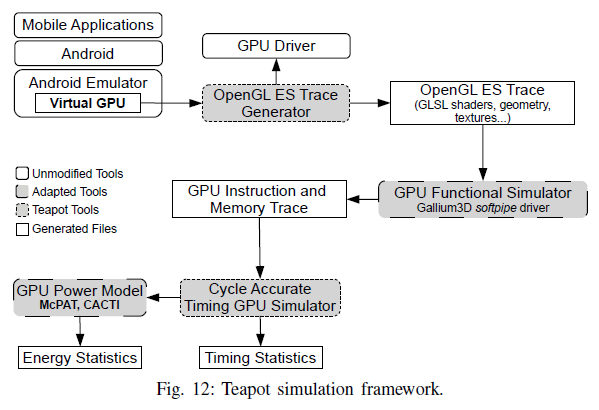
能耗计算模型:McPAT
Baseline GPU:ARM Mali-450 GPU

实验结果
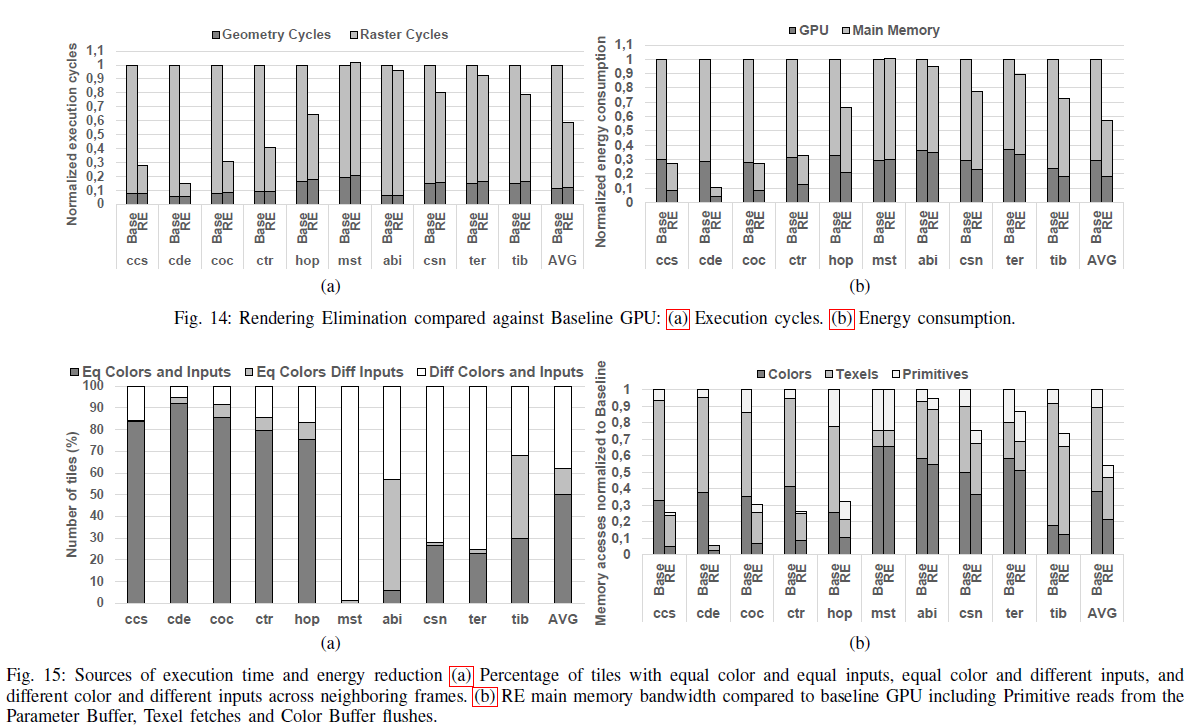
benchmark分为三类:css到top为静态相机的benchmark,mst为高动态相机的benchmark,abi到tib为部分为静态相机部分为高动态相机。
注意本文所提方法只能去除颜色和输入都相同的部分,即图15a中黑色的部分。
RE与Fragment Memoization和Transaction Elimination的对比
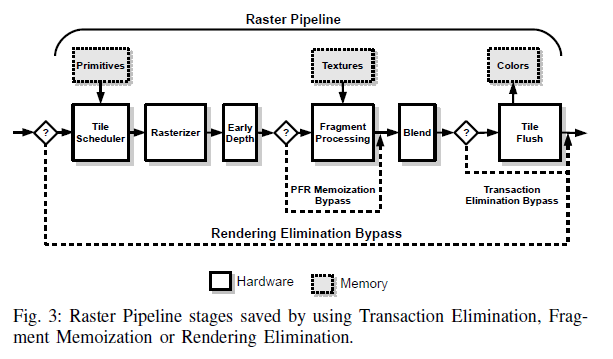
上图为三种结构的对比,可以看出RE可以根据drawcall的输入绕过整个Raster Pipeline,FM可以根据shader的输入绕过Fragment Shader,TE可以根据Color Buffer是否相同绕过写Frame Buffer的过程。
其中,值得注意的是 Fragment Memoization需要将shader输入的签名和最终输出的颜色缓存下来,然而由于最终输出的颜色所需额内存过大。因此直接存储一帧的输出颜色是不现实的,因此该方法使用了一种同时渲染两个连续帧的架构PFR,该架构可以保证同时渲染两个连续帧的相同块,以便于对比。然而,这只能去除同时渲染的帧的冗余,不能去除不同时渲染的连续帧的冗余。
RE与PFR-aided Fragment Memoization的对比试验如下:
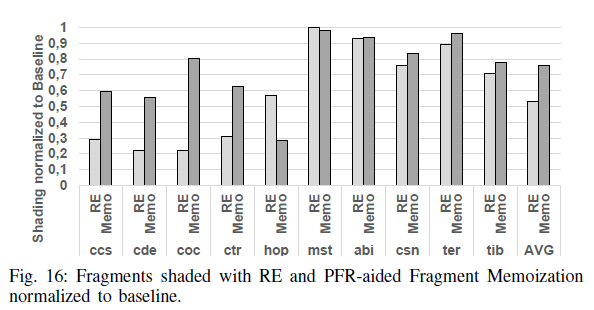
需要注意的是hop的benchmark,它渲染屏幕的大部分只有少数重复的fragment,而且这些fragment大部分都是完全黑的(可能考虑tile颜色相同时,有可能输入可能不同,RE只要输入有一点不同就要重新渲染,而FM只要颜色相同就不需要重新渲染。)
RE与Transaction Elimination的对比试验如下:
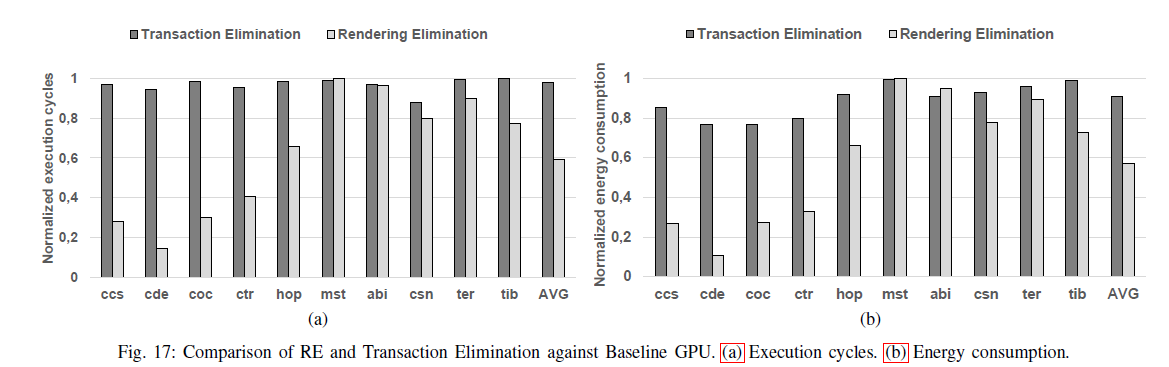
RE可以完全跳过raster pipeline 这可以节省大量的执行时间,而TE只能跳过写入Frame Buffer的执行时间,因此只要存在重复输入的tile,RE基本上优于TE。
总结
优点:RE相比于baseline gpu能平均提升1.74倍的运算性能,并可以在GPU和主存上的能耗分别减少38%和48%。
缺点:
- 无法检测输入不同但颜色相同的tile
- 计算Hash可能会产生碰撞对,但该几率极小,而且由于帧与帧间的连续性,hash相同两个tile也及其相似,此外由于帧率较高,人眼实际上是无法分别错误的。
以下是个人见解:该方法很好地用硬件去除了帧间计算的冗余,可以考虑利用该方法或者TE、FM结合H.264编码以提高编码效率。