原文链接
Equalizer 2.0–Convergence of a Parallel Rendering Framework
Equalizer简介
开发Equalizer应用的核心任务是将渲染的逻辑与应用程序逻辑分离。但需要调用rendering call时,请求Equalizer渲染一帧。由Equalizer分解和同步渲染任务,并在给定的渲染上下文下并行执行,该上下文是从特定系统配置中抽象出特定应用程序的渲染算法的核心实体。该渲染上下文指定了并行渲染的最小抽象,并给出以下参数:
Buffer:该参数受当前eye pass、eye separation和立体影像设置的影响。
Viewport:二维像素viewport限制渲染区域,该像素viewport受目的viewport和由sort-first分解的viewports的影响。
Frustum:由glFrustum定义,被用于
设置OpenGL的投影矩阵,该frustum受目的视角、sort-first、像素和子像素分解,头部跟踪矩阵和当前eye pass的影响。
Head Transformation:对于平面视角,这是一个单位阵;对于沉浸式渲染,被用于设置多视角矩阵中的视角部分。
Range:是一个区间在[0..1]的一维范围。该参数可选,被用于在sort-last渲染模式中渲染适当的数据子集。
View:包括摄像机、模型和其他应用状态等指定视角的数据。
这些配置决定应用程序如何并行执行,包括是哪个部分:描述物理渲染资源(节点、管道、窗口和通道)的部分、描述可视化设置的部分和描述这些资源如何被用于渲染的部分(该部分描述了渲染任务的分解、结果的合并)。
该执行模型是完全异步的,只有在严格需要的地方才会引入同步点。此外,在默认情况下,采用流水线的方式进行渲染,即一些资源在渲染下一帧,而其他的仍在完成当前帧,当渲染完成后便立即呈现其结果。许多操作都可以以流水线的方式运行,包括:应用程序事件处理、任务计算、负载均衡、渲染、图像回读、压缩、网络传输和合并。
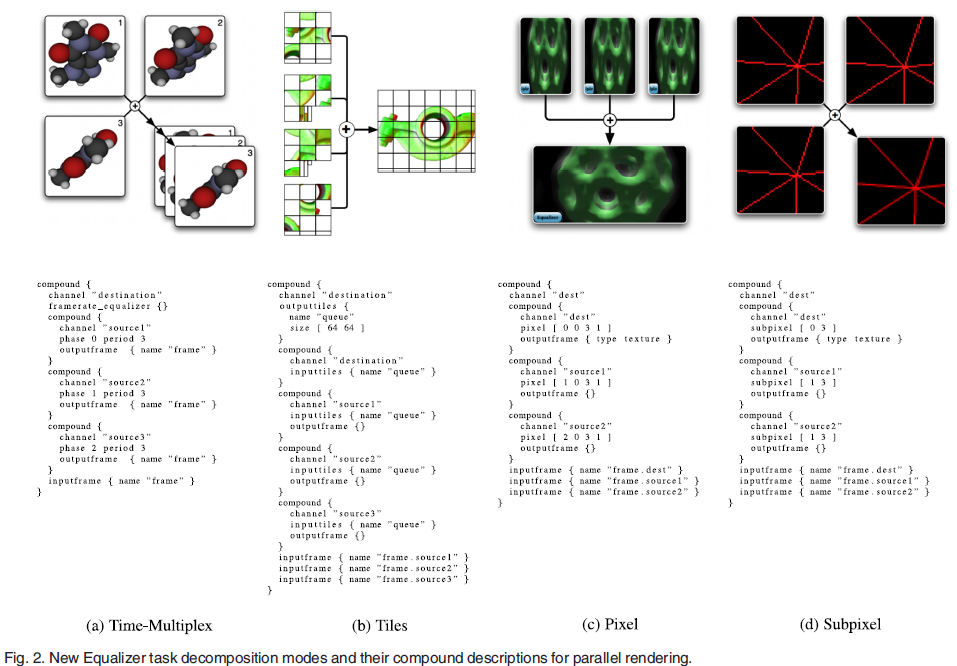
新的分解模式
时间复用
也被称为AFR或DPlex,但不能减少用户输入到屏幕输出间的延迟,更适用于无交互的渲染。此外,要在多线程、多GPU配置下工作,应用程序需要支持异步运行渲染线程。
tile and chunk
tile和chunk分别是sort-first和sort-last的变体,渲染任务放在服务器中心队列中通过轮询,被所有源通过进行排队和处理。
基于像素的分解
通过在图像空间中交叉行或列分解目标通道,每一个通道不能通过视椎体剔除减少几何负载,这是由于每个通道都使用了相同的视椎体。然而,片元的负载由于像素的交叉分布线性地减少,并保证负载均衡。该方法对Equalizer的应用程序透明,并默认使用模板缓冲区将对应像素传输到目标通道。该方法类似于sort-first,但并没有分解viewport。
基于子像素的分解
类似于像素分解,但是将单个像素分解为若干个子像素,每个通道负责一个子像素的渲染,最终通过求平均等方法合并像素。该功能对应用程序不是透明的。
Equalizer
sort-first和sort-last的负载均衡
Equalizer通过利用过去的渲染时间和帧与帧之间的连续性调整不同通道渲染视口的范围以保证负载均衡。Equalizer实现了两种不同的算法,load_equalizer和tree_equalizer。
load_equalizer
load_equalizer利用1D或2D的网格来存储一帧的计算负载,并映射到每一个通道的负载上,\frac{time}{area}表示该负载。通道被组织为一个二叉树。然后利用equalizer通过对网格上的开销的积分利用算法平衡每一层的两个分支的计算开销。
tree_equalizer
tree_equalizer也是使用二叉树来递归地进行负载均衡,通过对每个树上的所有节点进行累加,并使用其为每棵子树调度一个平衡的负载时间。这个算法没有假设2D或1D的负载分布,只是尝试纠正不平衡的渲染时间。
splite mode
splite mode配置tile的布局:通过二叉树分割代替坐标轴的分割,以生成紧凑的2D tile。
Cross-Segment 负载均衡(CSLB)
Cross-Segment优化n个渲染资源到m个输出通道的资源调度。
view equalizer与平衡各个输出通道的load equalizer一起工作。它监视跨输出共享源的使用情况,并激活他们一平衡所有输出的渲染时间。CSLB的独特之处在于它支持平面和非平面可视化系统的负载均衡,以及将渲染资源灵活地分配到各个输出通道。
动态帧分辨率(DFR)
DFR Equalizer能够通过动态调整渲染分辨率以保持稳定的帧率,当性能允许的情况下,可能会采用更好的采样方法(比如supersample)来提升画质。
Frame Rate Equalizer
framerate Equalizer通过延迟swap buffer的交换时间以使得输出的帧率变得平滑,被用于平滑不规则的应用程序渲染算法。
优化
Region of interest
感兴趣的区域是屏幕中显示的内容,通过使用ROI来优化load_equalizer,使得load equalizer使用ROI将负载网络细化到包含数据的区域(这里的意思可能是只对自己负责的渲染区域的数据进行处理),以减少回读和网络传输。
异步合并
作者并没有针对这一点说明很多,只说明了异步合成是对带有合成操作的渲染的流水线化。这里的合成操作包括图像回读、网络传输和将图像从并行运行的线程装配到渲染线程。
下载和压缩插件
合成步骤的压缩对性能来说是至关重要的一步,不仅可以应用到网络传输步骤,还可以应用于GPU到CPU间的传输。Equalizer支持多种压缩算法,这些算法均被实现为运行时加载的插件,并允许扩展。
线程同步模型
实现三种线程模式:完全同步,绘制同步同步和异步
完全同步:所有线程总是执行同一帧,这使得渲染线程能够从所有的操作中读取共享数据,但会获得更低的性能。
绘制同步:所有线程的绘制操作同步,这使得渲染线程在执行绘制操作时可以读取共享数据,但合并时不行。该模式允许多GPU的机器上的渲染合并和数据同步能够相互覆盖。
异步:所有线程异步执行,渲染线程可以在任何时间渲染不同的帧。该模式最快,但需要应用程序在每个渲染线程中拥有每个可变对象的实例。
后续是应用,待对Equalizer进行全面了解后再更新,暂略
总结
本文最值得关注的点在于提出了不同的几种并行渲染模式,其中基于像素划分和子像素划分的模式能够达到较好的负载均衡,但考虑可能在顶点着色器上会存在冗余计算。