原文链接
Visibility Rendering Order:Improving Energy Efficiency on Mobile GPUs through Frame Coherence
论文要解决的问题
从硬件层面解决early-z在渲染物体顺序不是从前到后时的overdraw问题。
经典Graphic Pipeline的回顾
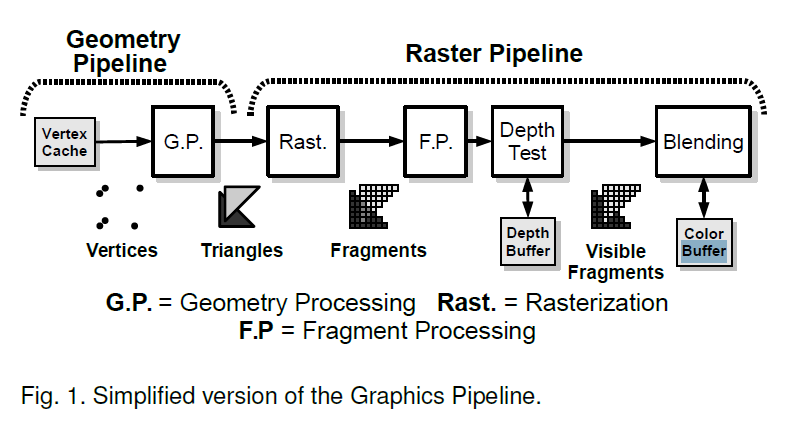
传统的深度检测在片元着色阶段会产生不必要的计算量(overdraw)
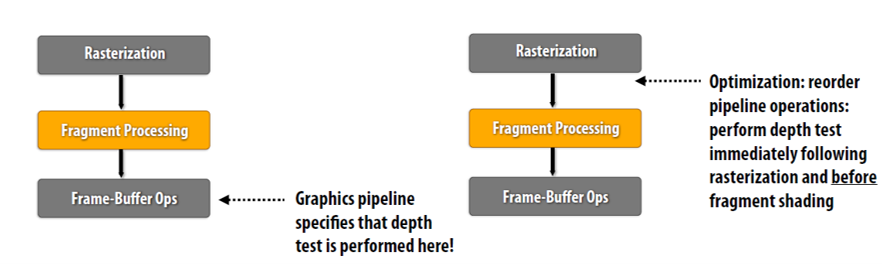
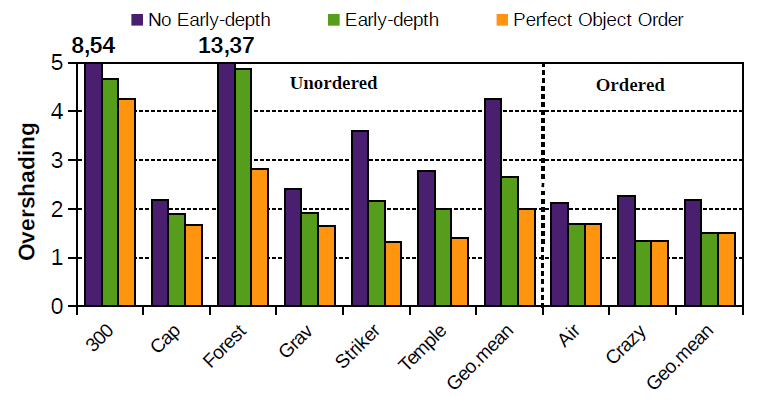
如果将深度检测提前至片元着色之前(early-z),没有通过深度检测的片元,则不需要进行片元着色。但是只有当物体的渲染顺序为从前到后时,才能完全避免overdraw。但是,大多数情况下不会通过软件对物体进行排序。下图是在不同的渲染场景下,No Early-z和early-z的渲染效率的对比。其中Unordered表示物体没有进行排序,Ordered表示物体已经被排序。图中的Overshading表示平均每个像素需要渲染多少个片元(包括透明物体,注意early-z只优化不透明的物体)
Early-z常见的两种改进措施
- z-prepass:
- 是一种软件技术
- 方法:将一帧分成两次独立的渲染。第一次渲染只对不透明的objects的位置信息进行光栅化,且在Fragment Shader中不做任何处理(即所得最终结果为一帧每个pixel的深度值),并将其结果存入depth buffer。第二次渲染利用第一次渲染所得的depth buffer进行early depth检测,并将通过检测的fragment进行Fragment Shader。
- 优点:只会渲染所有最终可见的不透明fragment所对应的像素,将overshading降到最小。
- 缺点:需要进行两次Vertex Shader、光栅化和深度检测。
- Deferred Rendering:
- 是一种硬件技术
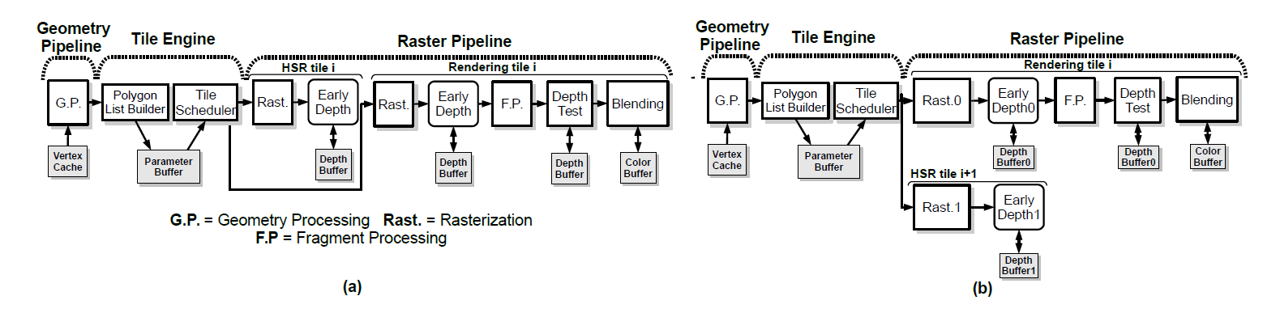
- 方法:将一帧分成tile(硬件中过程),并在early-depth之前增加hidden surface removal(HSR)阶段,在这个阶段中只对一个tile中的objects的位置信息进行光栅化,并将结果进行深度检测,最终写入depthbuffer中。在此之后进行正常的光栅化、early-depth和fragment Processing。如下图,deferred rendering有两种实现方式,图(a)为串行方式,这种方式会产生额外的时间开销,图(b)为并行方式。
文献所提方法 Visibility Rendering Order
- 假设:下一帧objects的深度顺序(Visibility Order),与当前帧相差较小。(帧间的连续性,文章作者通过实验发现该情况发生的概率为99%)
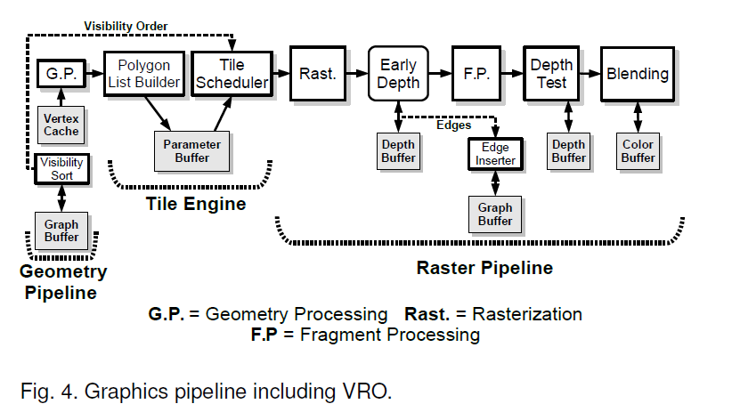
实现过程:
根据objects的深度关系构建Visibility Graph。具体过程为,在对第N帧进行early-depth的过程中得到不同objects在同一像素位置的深度关系,将该深度关系作为一条边(edges)通过edges Inserter单元构建一个有向图,并将该信息以邻接表的形式存入Graph buffer中。
对Visibility Graph执行拓扑排序算法,生成一个关于objects的front-to-back的List,第N+1帧将按该顺序对objects进行渲染。
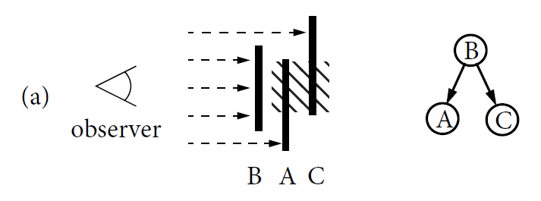
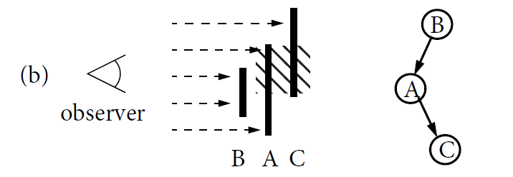
- 拓扑排序算法:该算法只能适用于有向无环图,然而应用场景中可能生成有环图(比如物体自遮蔽、两个objects相互遮蔽、两个物体以上相互遮蔽)

- 破除环路方法:
- 对于自遮蔽:不为其建立edge;
- 对于两个objects相互遮蔽:仅记录其中的一组关系。比如object A与B相互遮蔽产生(A,B)和(B,A)那么只记录(A,B);
- 对于两个物体以上的相互遮蔽:正常生成Graph,在拓扑排序算法遇到环路时,选取入度最小的节点进行处理,然后正常处理后续步骤。经实验表明这种情况占13%。
- 拓扑排序算法:该算法只能适用于有向无环图,然而应用场景中可能生成有环图(比如物体自遮蔽、两个objects相互遮蔽、两个物体以上相互遮蔽)
Visibility Rendering Order的调整:
- 对于前一帧有但当前帧没有的objects:从List中移除;
- 对于前一帧没有但当前帧有的objects:放到List的末尾;
- 对于半透明的objects(这种情况不能通过深度检测进行去除,而需要通过blend过程对这些objects的颜色进行合成,从后向前渲染):在不透明的物体之后渲染,保证其相对位置顺序。
实现过程
Baseline TBR GPU
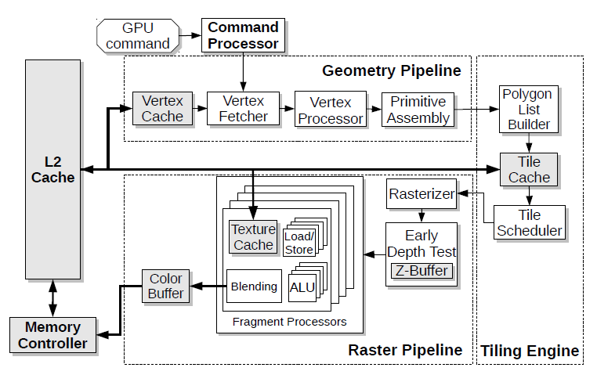
Objects经过Geometry Pipeline(包括视角转换、clipping、面剔除等),传入Polygon List Builder单元,该单元负责将图元调度到不同的tile当中,并将该信息存入Parameter Buffer中。该buffer存在显存当中,由tile cache进行访问。随后根据调度信息,进行Raster Pipeline。
该GPU有一个Vertex Processor和四个Fragment Processor。
Deferred Rendering TBR GPU
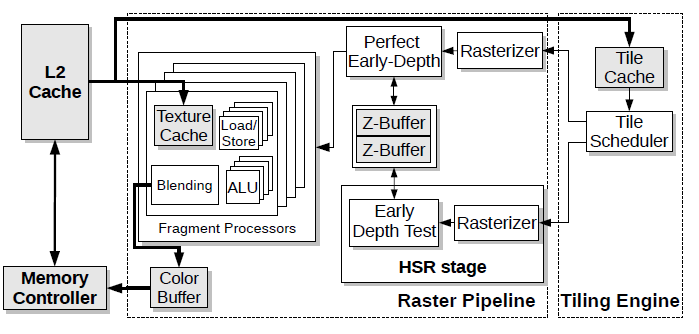
Tile i执行正常的渲染操作。HSR阶段用于计算Tile i+1的z-buffer的最终状态。当渲染Tile i+1时,两个z-buffer进行交换。
此外,Tile scheduler通过轮询的方式向两个光栅化器传输数据。在此期间,需要访问两次Tile Cache,因此平均数据传输时间与Baseline GPU和后续的VRO GPU相比较慢。
Visibility Rendering Order TBR GPU
Edge Inserter: 负责插入边,并将其存入Graph buffer中。
Edges Filter:由于Early-Depth过程可能产生大量相同边,因此可以通过该模块对边进行一个初步过滤。
Visibility Sort unit:执行拓扑排序算法,其结果用于下一帧渲染的object的排序。
VRO TBR GPU的实现细节
- Graph Buffer:由于Visibility Graph过于稀疏,因此Graph Buffer以邻接表的形式进行组织。

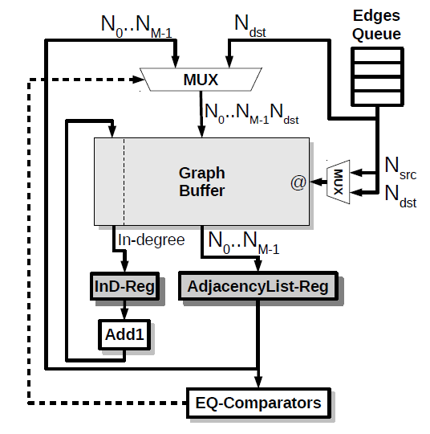
Edge Inserter
将边(Nsrc,Ndst)插入Visibility Graph可分为以下三步:将节点Nsrc对应的entry从Graph Buffer存入Adjacency-Reg。
判断是否该邻接表中是否有这条边的信息(这个过程使用一组相等比较器只需要一个时钟周期便可)
- 如果已存在,则丢弃;
- 否则,长度信息加1,并将这条边的信息加入该邻接表,并存入Graph Buffer。
将Ndst对应的入度加1
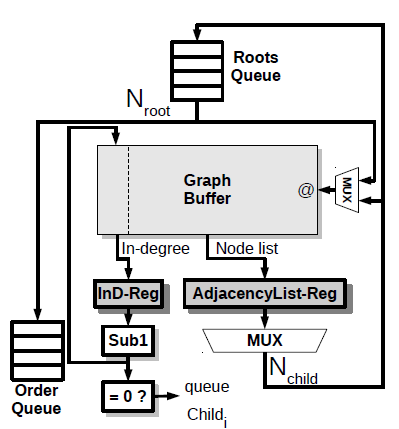
Visibility Sort Unit
初始化:将所有入度为0的节点对应的objects-id存入Roots Queue。将这个节点对应的邻接表读入AdjacencyList-Reg,并将对应的object-id通过Order-Queue存入Tile Scheduler
将该节点的Child节点的入度读入InD-Reg并减1,若此时入度为0,则将其存入Roots-Queue。
从Roots-Queue读入一个节点到AdjacencyList。
实验部分
- 使用Teapot GPU模拟器
- 使用McPAT框架计算能耗
实验结果:
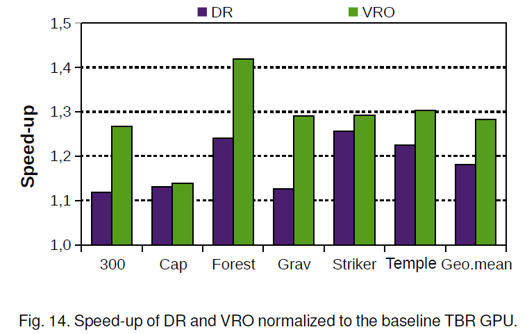
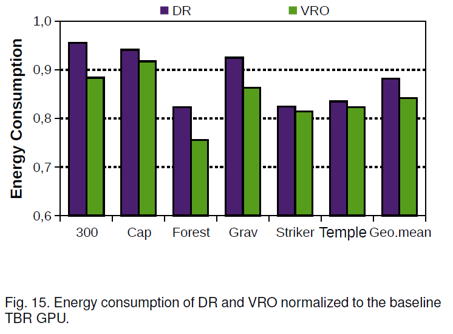
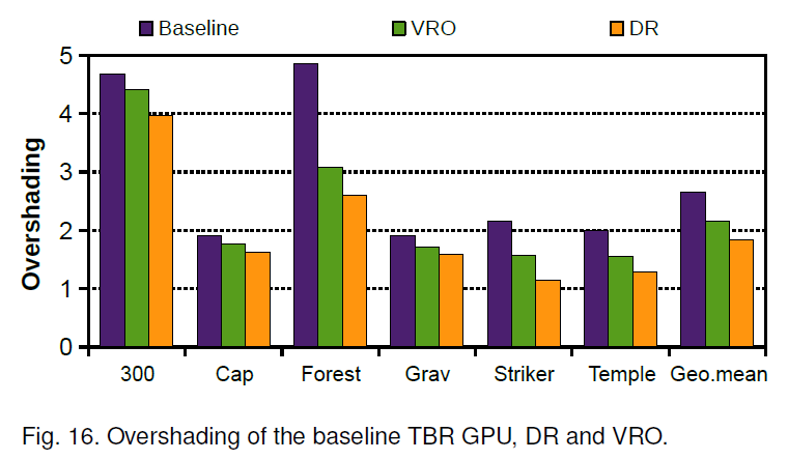
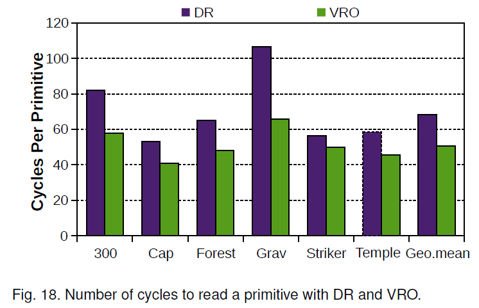
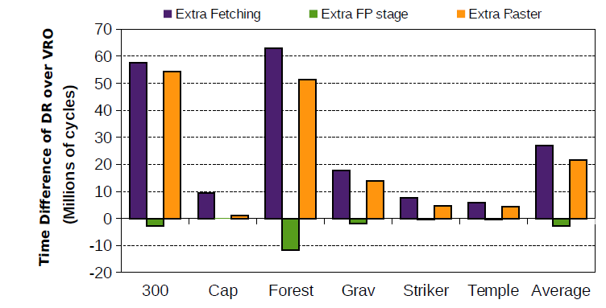
对于图18而言,需要注意DR读取一个图元较慢的原因是Tile scheduler通过轮询的方式向两个光栅化器传输数据。