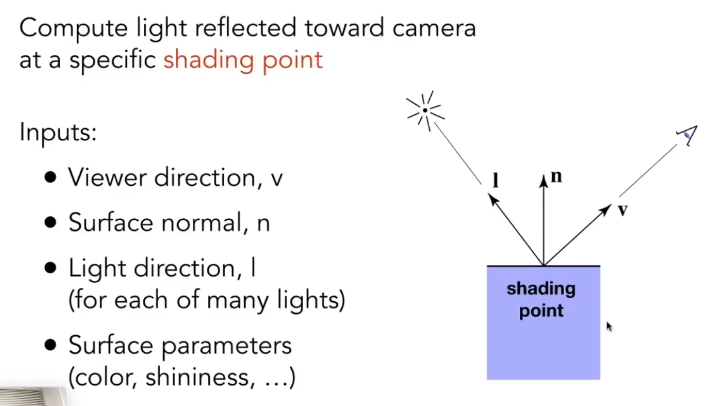
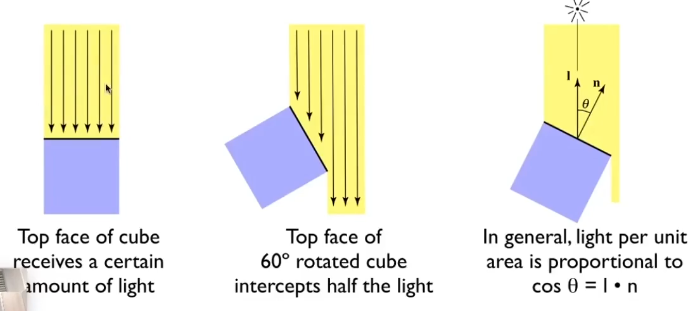
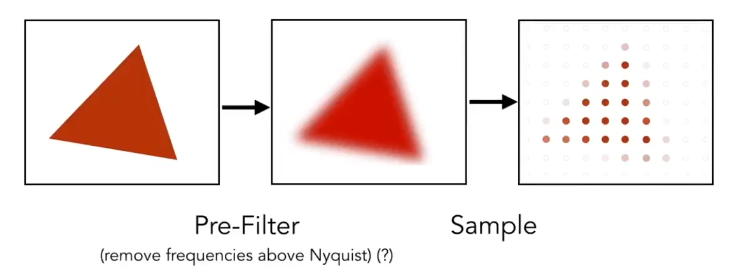
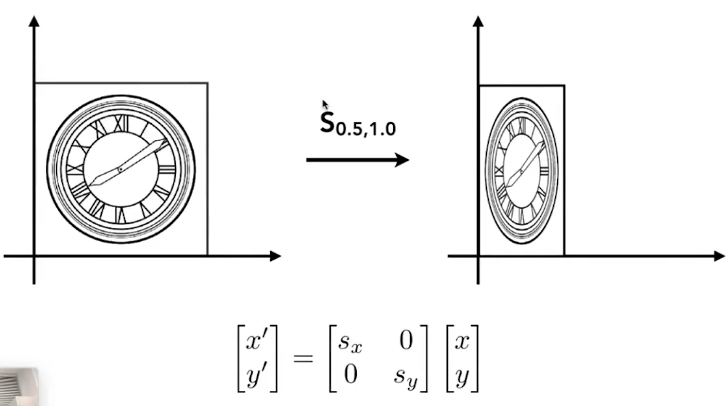
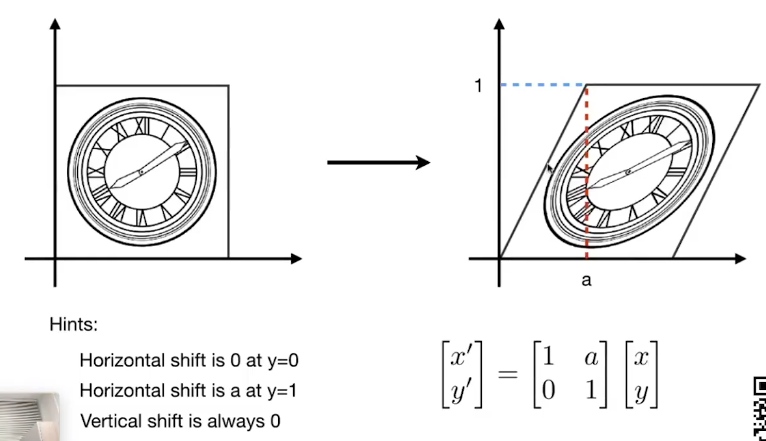
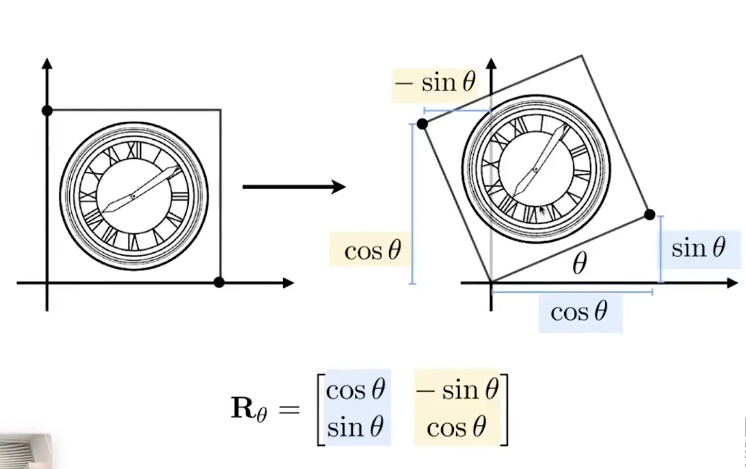
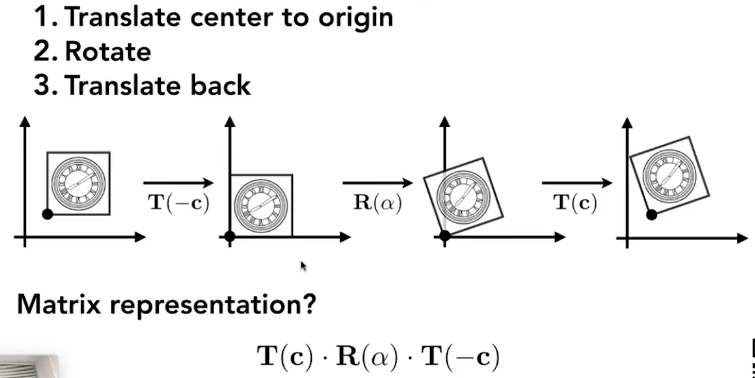
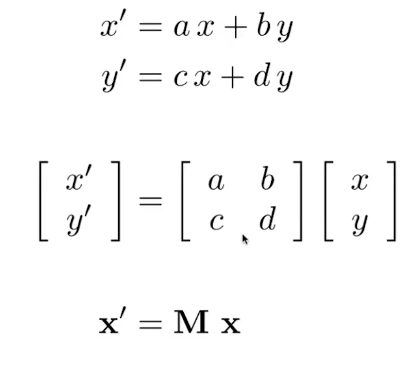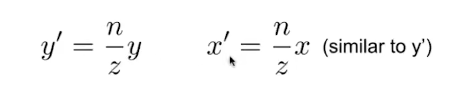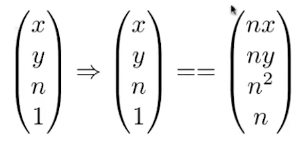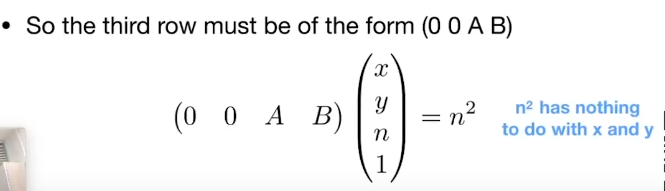说点什么
最近在忙着写实验用的程序,调bug调呀调不出来,正好下周组会轮我讲论文,不妨就看篇论文放松一下。
另外说一下,其实GAMES101的课程已经基本看完了,只是没有时间记笔记而已。
原文链接
DroidCloud:Scalable High Density Android™ Cloud Rendering
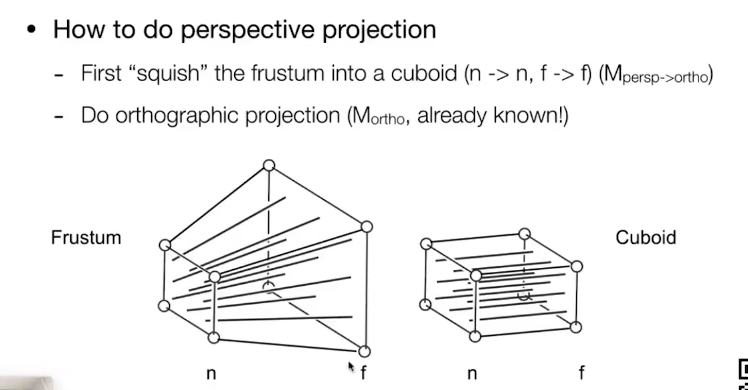
论文要解决的问题
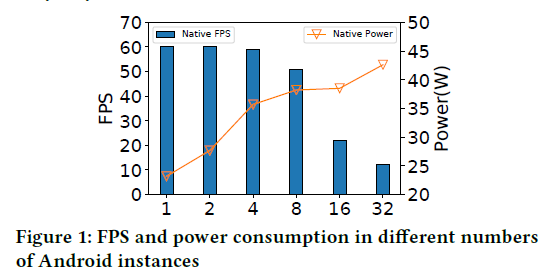
- 虽然传统的Android模拟器或Anbox可以将Android系统运行在云上,但会造成严重的性能损失,如下图所示,当多个Android的实例同时运行时,这种现象会尤为明显。
- 商用Android云渲染服务需要在一个服务器上提供高密度的服务,并且需要高可扩展性使其可以同时服务数百万的用户。
挑战:
- 系统对Android应用程序透明。
- 由于共享资源的相互干扰,因此需要对不同的Android OS进行隔离。
- 在实验中发现,有时当GPU的利用率达到100%时,CPU的利用率才达到30%,因此当一台服务器上有许多渲染任务时,服务器的GPU将会成为整个系统的瓶颈,DroidCloud通过使用远端的GPU来解决这个问题。
DroidCloud
为解决上述的三个挑战,本文实现的DroidCloud实现了三个技术:
- Android Virtual Device HAL shim (vHAL)layer:用于适应服务器结构并注入远端输入同时保证Android应用程序的透明度。
- 低开销的隔离策略:以减少不同OS的资源竞争,并平衡开销。
- 灵活的渲染调度:通过转发渲染命令,以同时使用远端GPU和本地GPU进行渲染。
此外,本文还做出了如下贡献: - 通过定制的Android OS优化单实例和跨实例资源开销
- 在Intel的Xeon平台上提供可以并行运行上百Android实例的云渲染系统
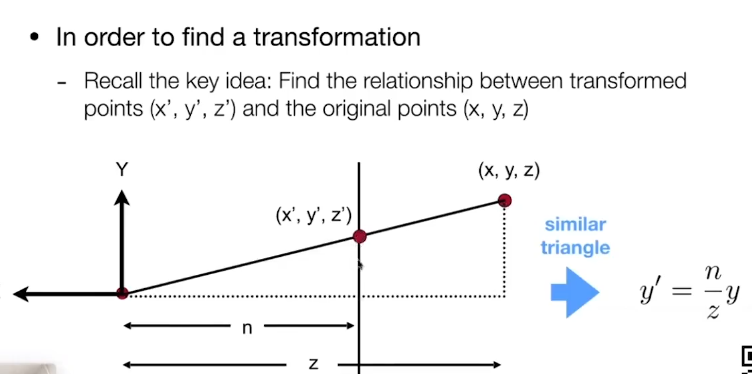
系统设计
DroidCloud由三个关键部分组成:DC-management、DC-Instance、DC-client。
DC-management:负责调度和管理DC-client和数百万在不同物理节点上的DC-Instance的生命周期。
DC-Client:远端设备,用于流媒体的解码,和捕捉用户的输入。
DC-Instance:是一个隔离的逻辑计算单元,每一个DC-Instance上有一个Android OS的实例。DC-Instance由三个子模块组成,分别是DC-runtime用于支持OS的运行时,DC-Rendering用于图形渲染和编码,DC-Network用于与对应的DC-client进行网络传输。
Virtual Android Device HAL
问题:由于Andorid平台和服务器间的I/O设备的兼容性问题,导致Android应用程序难以不做任何修改的情况下运行在服务器上。
HAL layer用于处理这个问题:
- Remote vHAL:用于将DC-client上的I/O设备数据重定向到DC-Runtime上。DC-Client和DC-Runtime根据数据的不同可以选择TCP、UDP或SCTP等不同的协议进行连接。
- Emulated HAL:用于模拟缺少的功能,比如通过以太网实现的WIFI
- Dummy HAL:用于模拟不太重要的硬件功能,比如振动器、蓝牙等。
Runtime Isolation
DroidCloud通过Linux container(namespace和cgroup机制)的解决方案将一个服务器上的Android系统进行隔离,以保证较少的资源共享和调度开销。除此之外,为andorid的特定功能提供了额外的扩展,如binder(一种Android特定的IPC(进程间通信)机制,由binder server、binder client和binder driver组成)。这是由于必须阻止从一个Android实例到其他实例的IPC。通过创建binder设备节点并将其分配到不同的DC-Instance,其提供不同实例间的隔离。
Flexible Rendering
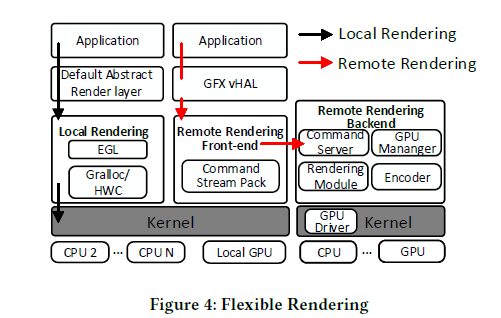
因此DroidCloud实现了本地渲染和云端的远程渲染。本地渲染是指通过本地的计算节点进行渲染,远程渲染是指利用其它计算节点进行渲染。
本地渲染:通过默认的渲染管线进行渲染。
远程渲染:基于OpenGL的API转发策略。DC-rendering重定向所有的渲染调用到DC-Rendering前端模块。前端模块将参数和数据缓存进行打包,并将其通过TCP/IP或RDMA通道发送至被分配的GPU所在的服务器上。远程渲染后端包含4个模块:
- Command Server:作为TCP/IP服务器接收前端发来数据包,并进行解包。
- GPU Manager: 管理与该服务器关联的GPU,以进行任务调度。
- Rendering Module:负责GPU渲染的软件驱动。
- Encoder:负责编码的软件驱动。
经过编码的视频流将会被送回前端进行流分组,最终发送至客户端。
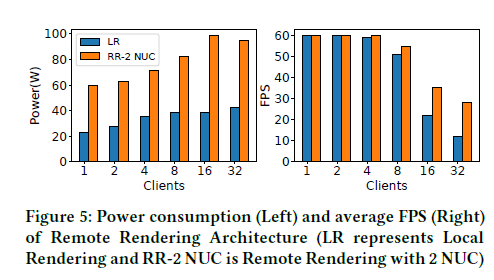
由上述实验可得,远端渲染可以避免单片SoC的功率限制(40W)。
优化
减少资源使用可以提高云渲染策略的密度。DroidCloud通过多种方法减少资源使用,包括简化单个实例的DC-Runtime和跨实例的资源共享。
单实例的减少资源使用
Android OS在丰富的I/O设备和硬件特性上配备了多种服务和应用。但是云渲染不需要其中的一些应用和服务,因此可以为使用目标进行定制。
Android守护程序Ueventd依赖来自kernel的确切消息来创建设备节点。这种实现在客户端可以运行的很好,但在由数百个DC-Runtime实例的DroidCloud,会产生“消息风暴”,这会随着实例数量的增加而降低DroidCloud的启动速度,因此为Ueventd创建一个固定的设备列表,而不是通过与kernel通信。
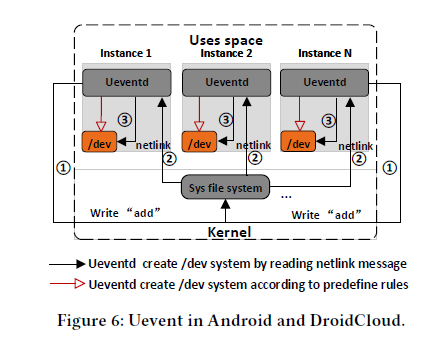
通过在DroidCloud中为不重要的特性实现确定的静态工作区。比如,DroidCloud通过AC power(交流电源)模拟电池,并通过避免监控更新以节省CPU的周期。此外,删除蓝牙和多用户等超过20个进程,以节省管理开销和DC-runtime中超过100MB的内存占用。
备注:与Linux相同,Android中的应用程序通过设备驱动访问硬件设备。设备节点文件是设备驱动的逻辑文件,应用程序使用设备节点文件来访问驱动程序。
在Linux中,运行所需的设备节点文件被被预先定义在“/dev”目录下。应用程序无需经过其它步骤,通过预先定义的设备节点文件即可访问设备驱动程序。
但根据Android的init进程的启动过程,我们知道,Android根文件系统的映像中不存在“/dev”目录,该目录是init进程启动后动态创建的。
因此,建立Anroid中设备节点文件的重任,也落在了init进程身上。为此,init进程创建子进程ueventd,并将创建设备节点文件的工作托付给ueventd。
ueventd通过两种方式创建设备节点文件。
第一种方式对应“冷插拔”(Cold Plug),即以预先定义的设备信息为基础,当ueventd启动后,统一创建设备节点文件。这一类设备节点文件也被称为静态节点文件。
第二种方式对应“热插拔”(Hot Plug),即在系统运行中,当有设备插入USB端口时,ueventd就会接收到这一事件,为插入的设备动态创建设备节点文件。这一类设备节点文件也被称为动态节点文件。
跨实例的减少资源使用
通过共享内存和共享编译代码以减少内存和编译成本。
主动文件页去重
每个Android映像由系统分区映像(system.img)、供应商分区映像(vendor.img)和根文件系统(rootfs)。其中系统分区映像和供应商分区映像对于每一个DC-Instance是完全相同的。因此,如果实例之间只共享一个副本,那么存储和页面缓存的成本将得到节省。
layered on write(LOW)技术被用于这种文件页去重,如下图所示,为减少文件映射内存(以及页缓存)的开销,DroidCloud.image是只读的,不同的DC-Instance使用相同的映像,以减少内存缓存的开销。
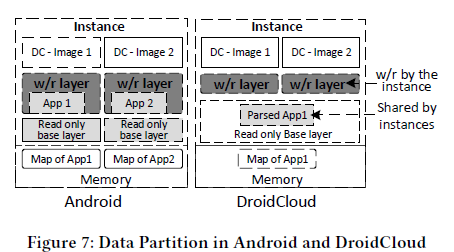
Android中的分层数据(layered data)用于包含Android系统和应用程序产生的读写数据。为更加灵活地管理这些数据,这些数据分区被移出DroidCloud映像,并保存在本地或中央文件系统中。为了进一步地减少内存缓存开销,分层数据被实现为一个Overlay file system(和docker类似)。其中基本的公共分层数据被保存为只读层,由不同的Android实例共享。可写层在基本层的顶部。分层数据的一个重要用途是共享应用程序的安装。
AOT二进制共享
AOT(Ahead Of Time)运行前编译:
在程序运行前编译,可以避免在运行时编译性能消耗和内存消耗。
通过跨实例应用程序安装,减轻存储和内存占用的开销。在同一组核心上运行多个实例时,应用程序本地库只有一个副本,因此这种共享可以减少指令的cache miss。
实验部分
本文在实验中主要关注一下三个方面:
- 不同规模场景下CPU、GPU、内存和磁盘的资源开销
- benchmark的性能
- 所提到的优化技术在大规模场景中的好处
实验平台如下: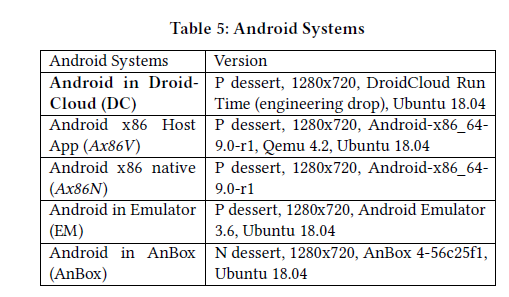
其中Android x86 native是一款标准的Android操作系统,具有完整的功能配置。Emulator和AnBox是为在Linux环境中运行应用而定制的运行库。
实验所用Benchmark如下: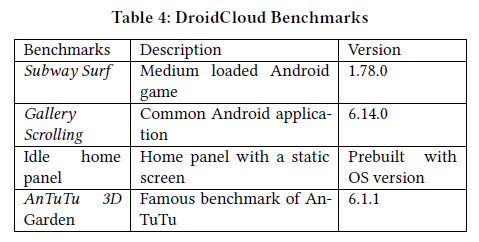
单个Android实例baseline
本实验对运行单个Android实例的项目进行横向比较,作为实例平均资源利用率的baseline。
下图展示了CPU、GPU、内存和磁盘在Gallery Scrolling在60FPS下和idle home panel在无屏幕刷新情况下的利用率。可以发现,DroidCloud作为定值的运行库相比于全功能配置具有较低的资源利用率。
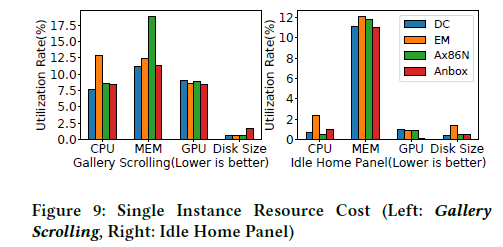
小场景下的DroidCloud
本实验是对运行多个Android实例的项目进行横向比较,目的是在保证QoS的情况下评估每个实例资源开销的可扩展性。
下图展示了本机操作系统运行1、2、4、8和16个实例时典型用例的帧率和延迟。注意Ax86V没有锁帧到60帧,因此在实例数量较少时,显示的性能较好。可以发现,由于DroidCloud采用了深度资源共享的策略,在基本容器实现的基础上提高了可扩展性。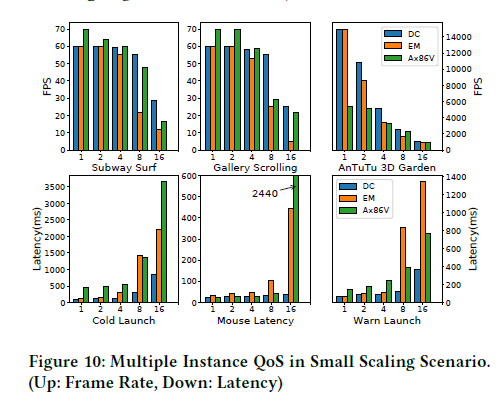
下图展示了在subway suf这个benchmark上,不同实例数量情况下的平均资源利用率。可以看出,由于好的资源共享设计,当实例数量为2资源利用率由明显下降,相对于其他的解决方案实现了更好的性能和QoS。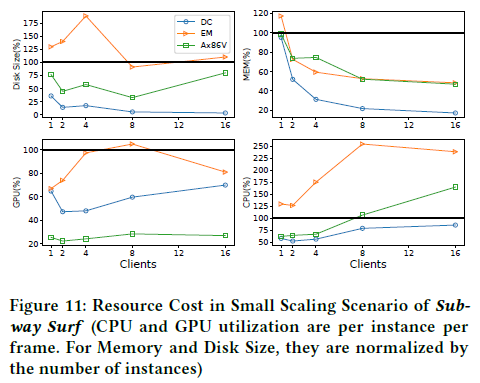
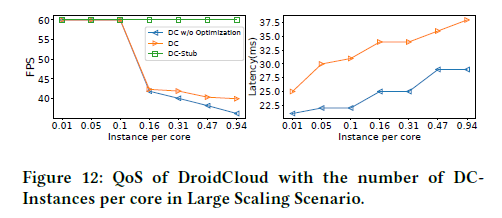
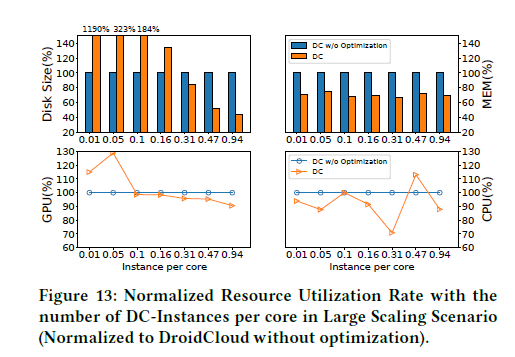
大场景下的DroidCloud
本实验是对DroidCloud在大规模场景下的垂直比较。DroidCloud、具有远程渲染的DroidCloud(DC-stub)和没有进行资源共享优化的DroidCloud(DC w/o Optimization)进行比较。
下图分别展示了在不同实例数量下的帧率、延迟和不同资源的归一化利用率。对比表明,DroidCloud在高密度场景下有非常好的可扩展性。